
最近一段时间,全球AI大模型赛道,进入“微创新+重落地”的深水区!
海外“三高”:高算力、高参数、高投入,继续抬升基座天花板;国内“三快”:快迭代、快场景、快降本——把差距压进一个季度。
两条路线在近三个月里跑出不同曲线,折射出中美竞速已从“追参数”转向“拼生态”。


8月7日,OpenAI正式推出GPT-5,采用统一系统架构,整合高效基础模型、深度推理模块和实时路由系统。
官方数据显示,GPT-5在LongFact、FActScore等开放式事实基准上的幻觉率仅为o3的1/6;
在CharXiv“无图测试”中,面对不存在图片仍自信回答的比例从o3的86.7%骤降到9%。
同日,GPT-5全线登陆Azure AI Foundry,提供272k上下文旗舰版、128k多模态对话版及nano边缘版,并原生嵌入GitHub Copilot与VS Code,单次请求可调用128种工具,率先把“模型即操作系统”推向数千万开发者。
谷歌Gemini 2.5 Pro则携Veo 3视频生成模型迎战,在Long Video Bench领先Runway Gen-4 12%,继续用多模态长板牵制OpenAI。
算力、工具链、用户黏性三线并举,海外头部正把技术红利转化为平台护城河。
中国:DeepSeek V3.1闪电迭代
通义万象多端开花
面对算力封锁,国产模型把“降本增效”写进基因。
8月21日,DeepSeek发布V3.1,采用“混合推理”架构:同一参数体可一键切换“思考/非思考”双模式,思维链压缩20%–50% token仍保持R1-0528同等精度;Code Agent在SWE基准提升18%,Search Agent在browsecomp多跳检索任务大幅领先前代。
9月22日推出的V3.1-Terminus更进一步,把“人类最后考试”分数从15.9拉到21.7,仅次Grok 4与GPT-5,中英文混杂与异常字符问题基本解决。
Base与Chat模型同步开源于Hugging Face、魔搭,840B增量token+UE8M0 FP8精度,把训练成本再打八折。
同一时期,阿里“通义万象”多模态模型升级至2.5版,在Video-MMLU中文评测首超Gemini 2.5 Pro 6.8分;
国产昇腾910C集群支撑其20万卡稳定训练37天,FP16利用率63%,实现“国产算力+国产框架”闭环。
模型、芯片、框架三线并行,把海外一个季度的差距压到一个月。
Artificial Analysis 9月报告显示,中美顶尖模型在MMLU、MMMU、HumanEval三大基准平均差距仅0.3%,中文、长文本、工业编码等细分赛道国产已反超。差距背后,两条路线显性分叉:
1、技术路径
美国“AGI横向扩张”vs中国“纵向场景穿透”。前者追求一个模型打天下,后者让模型先扎进金融、政务、制造等垂直场景,用行业数据反哺基础模型。
2、商业路径
美国“闭源+平台税”vs中国“开源+生态快反”。OpenAI靠API涨价提升毛利率,国产模型用极致低价换开发者,再以云原生、一体机、Agent商店三层包装做增值服务。
3、资源路径
美国“高算力+高资本”vs中国“算法创新+国产替代”。当先进算力被限,国产模型用混合专家、稀疏注意力、KV-cache压缩把训练成本砍半。
短期看,中美大模型已进入“性能趋同、成本趋异”的新均衡:海外靠算力红利继续探顶,国产靠算法红利快速平权。
中期看,决定胜负的不再是单点指标,而是“芯片—框架—模型—场景”全栈速度。
三季度华为、阿里、海光、英伟达轮番“放大招”,把AI基建竞赛从幕后推到聚光灯下。与海外“单卡称王”的路径不同,中国呈现“百花齐放”的系统级突围:芯片、框架、集群、云原生同步创新,一条“东方算力曲线”正在形成。
1、华为:超节点“搭积木”,一年一代翻倍
今年年初,CloudMatrix 384超节点通过灵衢总线技术实现全光互联,把384颗NPU+192颗CPU焊成一台“超级服务器”,可横向扩展至16万卡集群。
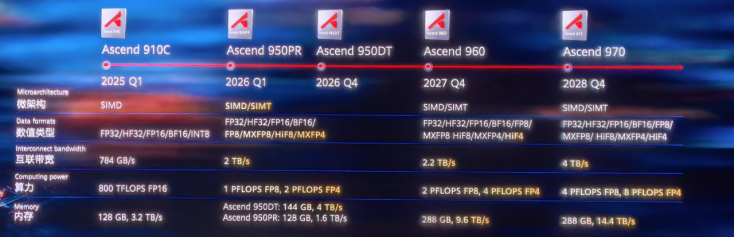
9月18日,全联接大会,华为把“AI算力全家桶”摆成一面机柜墙:昇腾950PR、960、970系列芯片首次公开路标,承诺“一年一代、算力翻倍”。
这背后,无疑是中国半导体先进制程已实现重大突破的技术底气!
2、阿里:自研PPU+万卡集群,云厂商反向定义芯片
8月29日,阿里平头哥宣布AI推理芯片PPU进入规模测试,兼容CUDA生态却由国内晶圆厂代工,片间互联带宽逼近H20,功耗持平A800。
新闻联播9月罕见披露:中国联通三江源项目已部署16384张PPU,提供1945P算力,年底扩至20000P,相当于“三个ImageNet”同时训练。
阿里云过去四个季度AI投入超1000亿元,未来三年再投3800亿元,形成“自研芯片+Qwen大模型+云分发网络”闭环,AI收入占比突破20%,连续八季三位数增长,验证了“云厂商反向定义芯片”的新范式。
3、英伟达:性能领先,但系统优势被追平
英伟达GB200 NVL72仍是单卡王者,FP8算力达1800 TFLOPS,高出昇腾910C 30%。
然而系统层面差距快速缩小:
华为CloudMatrix 384的BF16总算力达300 PFLOPs,是GB200的1.7倍,HBM容量更达3.6倍;
阿里PPU集群通过PCIe 5.0环形拓扑,把卡间带宽做“胖树”放大,实测千卡推理吞吐达到H20的92%。“
芯片-框架-集群”三段式竞争下,海外单卡优势被国产系统级创新部分抵消。
今年以来,中国AI基建呈现“芯片百花、集群千帆、云上万卡”的新格局:华为用超节点把百万卡集群做成“标准品”,阿里用云定义芯片让PPU成为“普惠算力”,海光、沐曦错位补位,英伟达从“唯一选择”变成“可选项”。
当算力不再被“卡脖子”而是被“拼积木”,国产AI的想象力才真正打开!

关注九方智投官方公众号,更有200+节爆款课免费送!
揭秘主力操盘手法,分享强势股秘诀,擒牛必学K线技巧……
有指标,有要诀,都是干货精髓!
识别下方二维码,关注九方智投公众号,回复“777”领取!

精彩推荐
扫描下方二维码,关注九方智投公众号,第一时间获取更多的行情资讯。
回复【3】,获取交易日《掘金龙虎榜》。
回复【518】,获取《K线课堂合辑》。
回复【666】,获取《庄家解码精彩合辑》。
回复【118】,获取《看图识股精彩合辑》。
回复【8】,获取《KDJ指标战法合集》。
回复【10】,获取《MACD使用技巧精彩合辑》。
